
ClickHouse built its business on one argument: stop running analytics on Postgres. The row store under your application was never meant to scan three hundred million rows for a dashboard, and a columnar engine does it in milliseconds. For years the migration pitch wrote itself.
So look at what shipped this month. ClickHouse now maintains an Apache-2 licensed Postgres extension, pg_clickhouse, which reached 0.3.2 stable on June 16. The same week, metered billing began on Postgres managed by ClickHouse, a fully managed Postgres service the company sells directly. The analytics vendor is shipping Postgres, and shipping the glue that lets Postgres talk to ClickHouse without a rewrite. That is not a new product line. It is a concession about who owns the front door.
The 'just use Postgres' decade hits a wall
The dominant database advice of the last few years compresses to three words: just use Postgres. Queues, full-text search, vector similarity, JSON documents, geospatial, pub/sub. Postgres absorbed all of it through extensions, and most teams never needed a second system. The advice is good. It stays good right up to the point where the workload stops being transactional.
Analytics is where the row store runs out of road. Postgres stores a row as a contiguous record, so a query that averages one column across half a billion rows still drags every other column through memory. Columnar engines flip that layout. ClickHouse reads only the columns a query touches, compresses each one tightly because neighbours share a type, and vectorizes the scan. On wide aggregations the gap is not a tuning problem. It is the storage format.
Postgres core has not stood still. Postgres 18 added asynchronous I/O so sequential scans stop waiting one block at a time, and Postgres 19 finally lets you steer the planner. Both help. Neither changes the fact that a 200-column fact table scanned for two columns pays for the 198 it never reads. The engine got faster at a game whose rules favour a different engine.
Which is why teams adopt ClickHouse. And then they hit the part nobody benchmarks: the migration. Analytics logic is not a tidy module you port over a weekend. It is years of SQL baked into dashboards, ORM call sites, scheduled jobs, and the one report finance refuses to lose. ClickHouse's own framing is blunt about it. Postgres is the single most common source of migrations onto ClickHouse, after self-hosted ClickHouse itself, and every one of those migrations means rewriting working SQL into a new dialect.
The extension exists to delete that rewrite. The question is how much of it actually disappears.
What pg_clickhouse actually does
Mechanically, pg_clickhouse is a foreign data wrapper. An FDW is a Postgres feature that makes an external system look like a set of local tables: you define a server, map your columns onto remote ones, and then write ordinary SQL against them. Postgres has had wrappers for other Postgres instances, for flat files, and for assorted databases for years. This one points at ClickHouse.
Setup is four statements. Create the extension, declare the remote server, map a user onto it, and import the schema.
CREATE EXTENSION pg_clickhouse;
CREATE SERVER taxi_srv FOREIGN DATA WRAPPER clickhouse_fdw
OPTIONS (driver 'binary', host 'localhost', dbname 'taxi');
CREATE USER MAPPING FOR CURRENT_USER SERVER taxi_srv
OPTIONS (user 'default');
CREATE SCHEMA taxi;
IMPORT FOREIGN SCHEMA taxi FROM SERVER taxi_srv INTO taxi;
SELECT count(*) FROM taxi.trips;From the application's side, taxi.trips is just a table. Your ORM does not know it lives in another engine. That is the whole trick, and it is also where a naive wrapper would fall apart, because the obvious implementation streams every row back into Postgres and aggregates locally. You would get the right answer at the worst possible speed.
What makes this version worth attention is query pushdown. Instead of pulling rows across, the wrapper translates as much of the query as it can into ClickHouse SQL and lets ClickHouse do the work. You can see it in the plan: a count(*) lands as a Foreign Scan with the aggregate itself pushed across.
EXPLAIN SELECT count(*) FROM taxi.trips;
Foreign Scan (cost=1.00..-0.90 rows=1 width=8)
Relations: Aggregate on (trips)The aggregate runs in ClickHouse and a single number comes back. That distinction, computing remotely versus shipping rows, is the entire value proposition. When pushdown works, you get ClickHouse performance through a Postgres connection. When it fails, you get a very expensive way to copy a table over the network.
Coverage has widened fast across the 0.x line. Filters, joins, and aggregates go across, including ordered-set aggregates like percentile_cont(). A FILTER (WHERE ...) clause maps onto ClickHouse's -If combinators rather than degrading to a local pass. Regex matching pushes down through an re2 path. Function pushdown is opt-in by default, a deliberate safety choice: a function only crosses the boundary when you allow it, so semantic differences between the two engines cannot silently change a result.
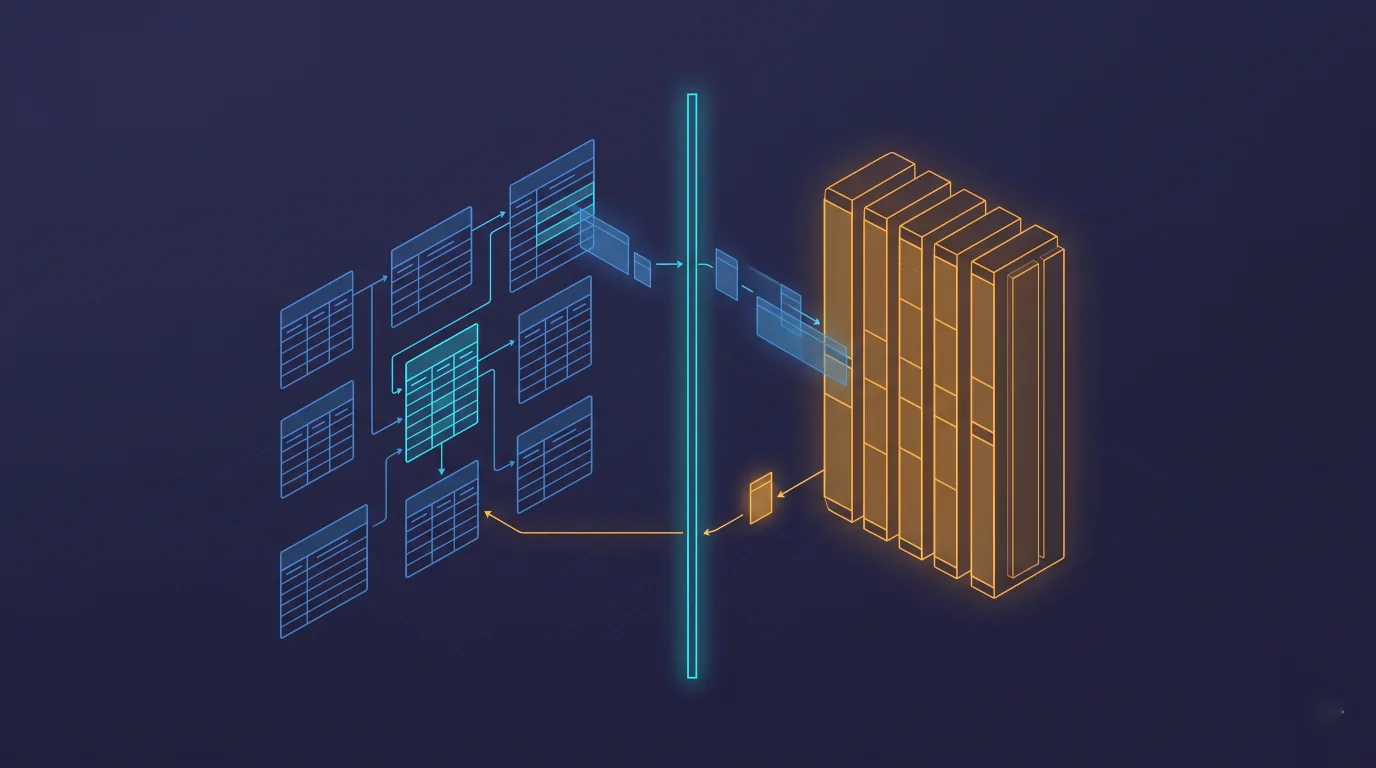
What does not push down is the real story
Read the roadmap, not the changelog. The operations that already push down are the easy half of analytical SQL. The operations that do not are the half real reports are made of: common table expressions, window functions, and many subquery shapes. These sit on the published roadmap, which is the polite way of saying they pull rows back to Postgres today.
TPC-H makes the boundary concrete. It is a standard set of 22 analytical queries over a normalized schema with real joins. On that suite, comfortably more than half of the queries push down fully, and the rest either degrade or never complete the pushdown. At least one query gets cancelled after a minute instead of finishing remotely. The pattern is consistent: the queries that lean on CTEs, correlated subqueries, and window functions are exactly the ones that fall back.
Set that against the headline benchmark. ClickHouse published results in February showing pg_clickhouse as the fastest Postgres analytics extension on ClickBench, tracking native ClickHouse closely across all 42 queries and landing only slightly behind it. That is a real result, and the post says so plainly, but read the methodology. ClickBench runs against a single denormalized table with no joins. It is the friendliest possible shape for pushdown: one scan, one aggregate, no relational gymnastics.
So both claims are true and they describe different worlds. On a flat, wide table the extension is nearly as fast as ClickHouse. On a normalized schema with joins and window functions, a meaningful slice of your queries quietly revert to dragging rows into Postgres. The speed you get depends entirely on whether your analytical SQL looks like ClickBench or like TPC-H, and production analytics looks far more like the latter.
| Operation | Pushed to ClickHouse? |
|---|---|
| WHERE filters | Yes |
| Joins, including SEMI JOIN | Yes |
Aggregates, incl. percentile_cont() | Yes |
| FILTER (WHERE ...) clauses | Yes, mapped to -If combinators |
| Regex matching | Yes, via an re2 path (opt-in) |
| Common table expressions | Not yet, on the roadmap |
| Window functions | Not yet, on the roadmap |
| Many subquery shapes | Partial, on the roadmap |
None of this makes the extension bad. It makes it young, and the 0.x version numbers are honest about that. What matters for an adoption decision is that the failure mode is silent. A query that pushed down cleanly can stop pushing down the moment someone adds a window function, and nothing errors. It just gets slow, and the slowness hides behind an FDW where it is easy to miss until a dashboard times out.
Make the boundary visible
The fix for a silent failure mode is to make it loud, and the instrument is EXPLAIN. When a query pushes down, the aggregate appears inside the Foreign Scan, as in the plan above. When it falls back, the shape inverts: the foreign scan returns a large row estimate, and the aggregate, sort, or WindowAgg node sits above it, running in Postgres over rows it just hauled across the network. The plan tells you which engine actually did the work, every time.
That makes pushdown something you can guard rather than hope for. Treat the plan of each hot analytical query as a regression test. Pin the critical ones in CI and fail the build when the work stops landing inside the foreign scan. Rows returned by the foreign server is a cheap second signal: a pushed-down aggregate returns one row or a small grouped set, while a fallback returns the raw rows, so a spike in rows-fetched is the fingerprint of a query that quietly came home.
Skip that discipline and the first sign of trouble is a dashboard that loaded in 200 ms last week and takes thirty seconds today, after a change nobody flagged because nothing broke. On a young extension where the pushdown frontier moves release to release, the team that watches the plans is the team that gets to keep the convenience.
The managed-Postgres play behind the extension
The extension is the visible half. The strategy is Postgres managed by ClickHouse, which entered public beta in May and switched to metered, paid billing on June 15. It is a fully managed, NVMe-backed Postgres service with high availability, point-in-time restore, an alpha Terraform provider, and role-based access control. ClickHouse is, for the first time, selling Postgres itself.
Both halves interlock. The managed service runs native change data capture from Postgres into ClickHouse through ClickPipes, so transactional writes land in the columnar engine continuously. pg_clickhouse then sits on top as what ClickHouse calls the unified query layer, the thing that lets one application span Postgres transactions and ClickHouse analytics. The stated goal is to be the best home for OLTP and OLAP at once.
Engineering signals say this is a real investment, not a press release. Across the spring the extension switched its binary driver from the C++ clickhouse-cpp client to a header-only clickhouse-c library, cutting the compiled extension from 4.9 MB down to 1.4 MB and shortening build times. The June 16 release added compression options and explicit TLS control for the native protocol, plus compatibility with the Postgres 19 beta. That is the kind of unglamorous productization work that only happens when a team intends to operate something at scale.
There is a tell buried in the recommended architecture, though. For join-heavy analytics, the maintainers do not point you at live FDW joins. They point you at replicating your operational tables into ClickHouse, through CDC, and querying them there. The same pattern runs through the wider Postgres-to-everywhere sync world: move the data once, query it where it is fast. So the extension is the convenience layer for queries that push down cleanly, and CDC into ClickHouse is the performance path for the ones that do not. Both ship in the same managed product, which is the point.

HTAP, attempted from the other side
The dream of one database serving transactions and analytics has a name, HTAP, hybrid transactional and analytical processing, and a long graveyard of attempts. The recurring problem is that the two workloads want opposite physical layouts. Transactions want rows and fast single-record writes. Analytics wants columns and fast wide scans. Every HTAP system is a negotiation over that conflict.
What is new is the direction of the assault. Most HTAP attempts come from the transactional side reaching toward analytics. Postgres got columnar extensions and embedded query engines that run DuckDB inside the database. MySQL got HeatWave. TimescaleDB bolted column compression onto Postgres for time series. Each one keeps the OLTP engine as home base and tries to graft on a column store.
ClickHouse is coming the other way. It is the analytics engine reaching back to annex the transactional front door instead of replacing it. The implicit bet is sharp and probably right: the front door is not up for grabs. Application frameworks, ORMs and their query builders, auth libraries, migration tools, and a decade of operational muscle memory all assume Postgres. Asking a team to give that up to get faster analytics is a losing trade, and ClickHouse appears to have concluded it cannot win the interface war. So it stopped fighting Postgres and started selling it, while keeping the part it does win, the columnar scan, underneath.
When the two-engine split earns its keep
The honest decision rule starts with a prior question: do you have an analytics problem at all? A large share of teams that reach for a column store have a handful of slow queries that a missing index, a materialized view, or a read replica would fix. If Postgres alone can serve your dashboards, a second engine is operational debt taken on for a problem you do not have. Just use Postgres still wins more of these arguments than it loses.
Where the extension genuinely earns its place, and where it does not:
| Use pg_clickhouse when | Reach for plain CDC instead when |
|---|---|
| You already run a real OLAP workload in ClickHouse and have years of Postgres-dialect SQL you cannot afford to rewrite. | Your analytics are join-heavy and latency-sensitive, where today's pushdown gaps would bite on every report. |
| You want one SQL surface and one connection string for an app that spans transactions and analytics. | You can replicate operational tables into ClickHouse and query them natively, skipping the FDW round trip. |
| Your heavy queries are flat scans and aggregates that push down cleanly: ClickBench-shaped, not TPC-H-shaped. | You lean on CTEs and window functions, the shapes that quietly fall back to dragging rows into Postgres. |
Whichever path you take, you are running two engines now, and that is the cost the convenience layer hides. Two failure domains, two upgrade cadences, two security surfaces, two sets of metrics to read at 3 a.m. The managed service absorbs a real part of that, which is exactly why ClickHouse steers you toward it rather than the self-hosted extension. Run the extension on your own infrastructure and you own the whole operational surface. The smooth SQL experience does nothing to shrink it.
Postgres won the interface, even where it loses the workload
Strip away the product names and one fact remains. A columnar database vendor is now shipping a Postgres extension and a managed Postgres service. That is the strongest signal yet that Postgres has won the interface war even where it loses the workload. The column store still wins the scan. Postgres won everything around it: the dialect, the drivers, the ORMs, the mental model. ClickHouse read the board and chose to meet developers at the door they already use.
The open question is which path becomes the default. If the pushdown frontier closes fast, if CTEs, window functions, and subqueries start crossing the boundary reliably, the unified query layer turns into the obvious way to run analytics from a Postgres app. If it stalls, CDC into ClickHouse stays the path that actually performs, and the extension stays a convenience for the easy queries. Either way, the version number is the wrong thing to watch. Watch the pushdown coverage. That is where this story is being written.